Lately, I used to be making ready to ship an essential bottom-of-funnel (BOFU) e-mail to our viewers. I had two topic traces and couldn‘t determine which one would carry out higher.
Naturally, I believed, “Let’s A/B check them!” Nonetheless, our e-mail marketer shortly identified a limitation I hadn’t thought-about:

At first, this appeared counterintuitive. Certainly 5,000 subscribers was sufficient to run a easy check between two topic traces?
This dialog led me down an enchanting rabbit gap into the world of statistical significance and why it issues a lot in advertising choices.
![New Data: Instagram Engagement Report [Free Download]](https://no-cache.hubspot.com/cta/default/53/9294dd33-9827-4b39-8fc2-b7fbece7fdb9.png)
Whereas instruments like HubSpot’s free statistical significance calculator could make the mathematics simpler, understanding what they calculate and the way it impacts your technique is invaluable.
Under, I’ll break down statistical significance with a real-world instance, providing you with the instruments to make smarter, data-driven choices in your advertising campaigns.
Desk of Contents
What’s statistical significance?
In advertising, statistical significance is when the outcomes of your analysis present that the relationships between the variables you are testing (like conversion fee and touchdown web page kind) aren’t random; they affect one another.
Why is statistical significance essential?
Statistical significance is sort of a reality detector in your information. It helps you identify if the distinction between any two choices — like your topic traces — is probably going an actual or random probability.
Consider it like flipping a coin. In case you flip it 5 instances and get heads 4 instances, does that imply your coin is biased? Most likely not.
However should you flip it 1,000 instances and get heads 800 instances, now you is likely to be onto one thing.
That is the function statistical significance performs: it separates coincidence from significant patterns. This was precisely what our e-mail knowledgeable was making an attempt to elucidate once I advised we A/B check our topic traces.
Similar to the coin flip instance, she identified that what seems to be like a significant distinction — say, a 2% hole in open charges — won’t inform the entire story.

We wanted to grasp statistical significance earlier than making choices that might have an effect on our total e-mail technique.
She then walked me by her testing course of:
Group A would obtain Topic Line A, and Group B would get Topic Line B.
She’d observe open charges for each teams, evaluate the outcomes, and declare a winner.
“Appears simple, proper?” she requested. Then she revealed the place it will get tough.
She confirmed me a situation: Think about Group A had an open fee of 25% and Group B had an open fee of 27%. At first look, it seems to be like Topic Line B carried out higher. However can we belief this end result?
What if the distinction was simply attributable to random probability and never as a result of Topic Line B was actually higher?
This query led me down an enchanting path to grasp why statistical significance issues a lot in advertising choices. This is what I found:
This is Why Statistical Significance Issues
Pattern dimension influences reliability: My preliminary assumption about our 5,000 subscribers being sufficient was fallacious. When break up evenly between the 2 teams, every topic line would solely be examined on 2,500 individuals. With a median open fee of 20%, we‘d solely see round 500 opens per group. I realized that’s not an enormous quantity when making an attempt to detect small variations like a 2% hole. The smaller the pattern, the upper the possibility that random variability skews your outcomes.
The distinction won’t be actual: This was eye-opening for me. Even when Topic Line B had 10 extra opens than Topic Line A, that doesn‘t imply it’s definitively higher. A statistical significance check would assist decide if this distinction is significant or if it may have occurred by probability.
Making the fallacious determination is expensive: This actually hits residence. If we falsely concluded that Topic Line B was higher and used it in future campaigns, we would miss alternatives to have interaction our viewers extra successfully. Worse, we may waste time and assets scaling a technique that does not truly work.
By means of my analysis, I found that statistical significance helps you keep away from performing on what might be a coincidence. It asks an important query: ‘If we repeated this check 100 instances, how doubtless is it that we’d see this identical distinction in outcomes?’
If the reply is ‘very doubtless,’ then you possibly can belief the end result. If not, it is time to rethink your method.
Although I used to be desperate to be taught the statistical calculations, I first wanted to grasp a extra elementary query: when ought to we even run these assessments within the first place?

The right way to Check for Statistical Significance: My Fast Determination Framework
When deciding whether or not to run a check, use this determination framework to evaluate whether or not it’s well worth the effort and time. Right here’s how I break it down.
Run assessments when:
You will have a ample pattern dimension. The check can attain statistical significance based mostly on the variety of customers or recipients.
The change may impression enterprise metrics. For instance, testing a brand new call-to-action may immediately enhance conversions.
When you possibly can anticipate the complete check period. Impatience can result in inconclusive outcomes. I all the time make sure the check has sufficient time to run its course.
The distinction would justify implementation value. If the outcomes result in a significant ROI or decreased useful resource prices, it’s price testing.
Don’t run the check when:
The pattern dimension is simply too small. With out sufficient information, the outcomes gained’t be dependable or actionable.
You want speedy outcomes. If a call is pressing, testing might not be one of the best method.
The change is minimal. Testing small tweaks, like shifting a button just a few pixels, usually requires huge pattern sizes to indicate significant outcomes.
Implementation value exceeds potential profit. If the assets wanted to implement the profitable model outweigh the anticipated good points, testing isn’t price it.
Check Prioritization Matrix
Once you’re juggling a number of check concepts, I like to recommend utilizing a prioritization matrix to give attention to high-impact alternatives.
Excessive-priority assessments:
Excessive-traffic pages. These pages supply the biggest pattern sizes and quickest path to significance.
Main conversion factors. Check areas like sign-up types or checkout processes that immediately have an effect on income.
Income-generating components. Headlines, CTAs, or presents that drive purchases or subscriptions.
Buyer acquisition touchpoints. E mail topic traces, advertisements, or touchdown pages that affect lead era.
Low-priority assessments:
Low-traffic pages. These pages take for much longer to provide actionable outcomes.
Minor design components. Small stylistic adjustments usually don’t transfer the needle sufficient to justify testing.
Non-revenue pages. About pages or blogs with out direct hyperlinks to conversions might not warrant in depth testing.
Secondary metrics. Testing for vainness metrics like time on web page might not align with enterprise objectives.
This framework ensures you focus your efforts the place they matter most.

However this led to my subsequent massive query: as soon as you’ve got determined to run a check, how do you truly decide statistical significance?
Fortunately, whereas the mathematics would possibly sound intimidating, there are easy instruments and strategies for getting correct solutions. Let’s break it down step-by-step.
The right way to Calculate and Decide Statistical Significance
Resolve what you need to check.
Decide your speculation.
Begin gathering your information.
Calculate chi-squared outcomes.
Calculate your anticipated values.
See how your outcomes differ from what you anticipated.
Discover your sum.
Interpret your outcomes.
Decide statistical significance.
Report on statistical significance to your group.
1. Resolve what you need to check.
Step one is to determine what you’d like to check. This might be:
Evaluating conversion charges on two touchdown pages with completely different photos.
Testing click-through charges on emails with completely different topic traces.
Evaluating conversion charges on completely different call-to-action buttons on the finish of a weblog put up.
The chances are countless, however simplicity is essential. Begin with a selected piece of content material you need to enhance, and set a transparent objective — for instance, boosting conversion charges or rising views.
Whilst you can discover extra advanced approaches, like testing a number of variations (multivariate assessments), I like to recommend beginning with a simple A/B check. For this instance, I’ll evaluate two variations of a touchdown web page with the objective of accelerating conversion charges.
Professional tip: In case you’re curious in regards to the distinction between A/B and multivariate assessments, try this information on A/B vs. Multivariate Testing.
2. Decide your speculation.
In the case of A/B testing, our resident e-mail knowledgeable all the time emphasizes beginning with a transparent speculation. She defined that having a speculation helps focus the check and ensures significant outcomes.
On this case, since we’re testing two e-mail topic traces, the speculation would possibly appear to be this:

One other key step is deciding on a confidence degree earlier than the check begins. A 95% confidence degree is customary in most assessments, because it ensures the outcomes are statistically dependable and never simply attributable to random probability.
This structured method makes it simpler to interpret your outcomes and take significant motion.
3. Begin gathering your information.
When you’ve decided what you’d like to check, it’s time to begin gathering your information. Because the objective of this check is to determine which topic line performs higher for future campaigns, you’ll want to pick out an applicable pattern dimension.
For emails, this would possibly imply splitting your record into random pattern teams and sending every group a special topic line variation.
As an illustration, should you’re testing two topic traces, divide your record evenly and randomly to make sure each teams are comparable.
Figuring out the appropriate pattern dimension may be tough, because it varies with every check. A very good rule of thumb is to purpose for an anticipated worth better than 5 for every variation.
This helps guarantee your outcomes are statistically legitimate. (I’ll cowl how one can calculate anticipated values additional down.)
4. Calculate Chi-Squared outcomes.
In researching how one can analyze our e-mail testing outcomes, I found that whereas there are a number of statistical assessments obtainable, the Chi-Squared check is especially well-suited for A/B testing eventualities like ours.
This made good sense for our e-mail testing situation. A Chi-Squared check is used for discrete information, which merely means the outcomes fall into distinct classes.
In our case, an e-mail recipient will both open the e-mail or not open it — there isn’t any center floor.
One key idea I wanted to grasp was the boldness degree (additionally known as the alpha of the check). A 95% confidence degree is customary, which means there’s solely a 5% probability (alpha = 0.05) that the noticed relationship is because of random probability.
For instance: “The outcomes are statistically important with 95% confidence” signifies that the alpha was 0.05, which means there is a 1 in 20 probability of error within the outcomes.
My analysis confirmed that organizing the information right into a easy chart for readability is one of the best ways to begin.
Since I’m testing two variations (Topic Line A and Topic Line B) and two outcomes (opened, didn’t open), I can use a 2×2 chart:
Consequence
Topic Line A
Topic Line B
Complete
Opened
X (e.g., 125)
Y (e.g., 135)
X + Y
Did Not Open
Z (e.g., 375)
W (e.g., 365)
Z + W
Complete
X + Z
Y + W
N
This makes it simple to visualise the information and calculate your Chi-Squared outcomes. Totals for every column and row present a transparent overview of the outcomes in combination, setting you up for the subsequent step: operating the precise check.
Whereas instruments like HubSpot’s A/B Testing Package can calculate statistical significance robotically, understanding the underlying course of helps you make higher testing choices. Let’s take a look at how these calculations truly work:
Operating the Chi-Squared check
As soon as I’ve organized my information right into a chart, the subsequent step is to calculate statistical significance utilizing the Chi-Squared system.
Right here’s what the system seems to be like:
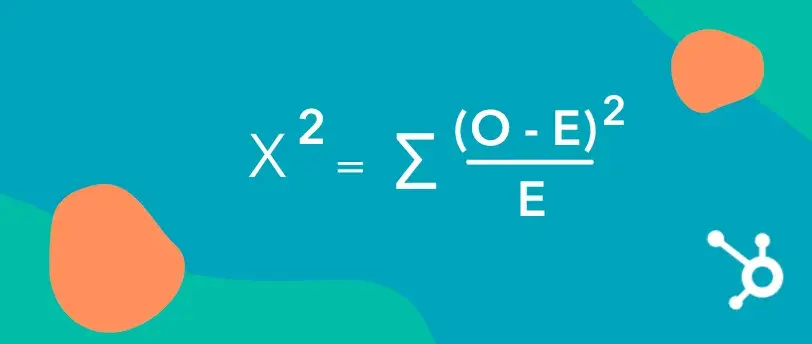
On this system:
Σ means to sum (add up) all calculated values.
O represents the noticed (precise) values out of your check.
E represents the anticipated values, which you calculate based mostly on the totals in your chart.
To make use of the system:
Subtract the anticipated worth (E) from the noticed worth (O) for every cell within the chart.
Sq. the end result.
Divide the squared distinction by the anticipated worth (E).
Repeat these steps for all cells, then sum up all the outcomes after the Σ to get your Chi-Squared worth.
This calculation tells you whether or not the variations between your teams are statistically important or doubtless attributable to probability.
5. Calculate your anticipated values.
Now, it’s time to calculate the anticipated values (E) for every final result in your check. If there’s no relationship between the topic line and whether or not an e-mail is opened, we’d anticipate the open charges to be proportionate throughout each variations (A and B).
Let’s assume:
Complete emails despatched = 5,000
Complete opens = 1,000 (20% open fee)
Topic Line A was despatched to 2,500 recipients.
Topic Line B was additionally despatched to 2,500 recipients.
Right here’s the way you set up the information in a desk:
Consequence
Topic Line A
Topic Line B
Complete
Opened
500 (O)
500 (O)
1,000
Did Not Open
2,000 (O)
2,000 (O)
4,000
Complete
2,500
2,500
5,000
Anticipated Values (E):
To calculate the anticipated worth for every cell, use this system:
E=(Row Complete×Column Complete)Grand TotalE = frac{(textual content{Row Complete} instances textual content{Column Complete})}{textual content{Grand Complete}}E=Grand Complete(Row Complete×Column Complete)
For instance, to calculate the anticipated variety of opens for Topic Line A:
E=(1,000×2,500)5,000=500E = frac{(1,000 instances 2,500)}{5,000} = 500E=5,000(1,000×2,500)=500
Repeat this calculation for every cell:
Consequence
Topic Line A (E)
Topic Line B (E)
Complete
Opened
500
500
1,000
Did Not Open
2,000
2,000
4,000
Complete
2,500
2,500
5,000
These anticipated values now present the baseline you’ll use within the Chi-Squared system to check in opposition to the noticed values.
6. See how your outcomes differ from what you anticipated.
To calculate the Chi-Sq. worth, evaluate the noticed frequencies (O) to the anticipated frequencies (E) in every cell of your desk. The system for every cell is:
χ2=(O−E)2Echi^2 = frac{(O – E)^2}{E}χ2=E(O−E)2
Steps:
Subtract the noticed worth from the anticipated worth.
Sq. the end result to amplify the distinction.
Divide this squared distinction by the anticipated worth.
Sum up all the outcomes for every cell to get your whole Chi-Sq. worth.
Let’s work by the information from the sooner instance:
Consequence
Topic Line A (O)
Topic Line B (O)
Topic Line A (E)
Topic Line B (E)
(O−E)2/E(O – E)^2 / E(O−E)2/E
Opened
550
450
500
500
(550−500)2/500=5(550-500)^2 / 500 = 5(550−500)2/500=5
Did Not Open
1,950
2,050
2,000
2,000
(1950−2000)2/2000=1.25(1950-2000)^2 / 2000 = 1.25(1950−2000)2/2000=1.25
Now sum up the (O−E)2/E(O – E)^2 / E(O−E)2/E values:
χ2=5+1.25=6.25chi^2 = 5 + 1.25 = 6.25χ2=5+1.25=6.25
That is your whole Chi-Sq. worth, which signifies how a lot the noticed outcomes differ from what was anticipated.
What does this worth imply?
You’ll now evaluate this Chi-Sq. worth to a crucial worth from a Chi-Sq. distribution desk based mostly in your levels of freedom (variety of classes – 1) and confidence degree. In case your worth exceeds the crucial worth, the distinction is statistically important.
7. Discover your sum.
Lastly, I sum the outcomes from all cells within the desk to get my Chi-Sq. worth. This worth represents the entire distinction between the noticed and anticipated outcomes.
Utilizing the sooner instance:
Consequence
(O−E)2/E(O – E)^2 / E(O−E)2/E for Topic Line A
(O−E)2/E(O – E)^2 / E(O−E)2/E for Topic Line B
Opened
5
5
Did Not Open
1.25
1.25
χ2=5+5+1.25+1.25=12.5chi^2 = 5 + 5 + 1.25 + 1.25 = 12.5χ2=5+5+1.25+1.25=12.5
Examine your Chi-Sq. worth to the distribution desk.
To find out if the outcomes are statistically important, I evaluate the Chi-Sq. worth (12.5) to a crucial worth from a Chi-Sq. distribution desk, based mostly on:
Levels of freedom (df): That is decided by (variety of rows −1)×(variety of columns −1)(variety of rows – 1) instances (variety of columns – 1)(variety of rows −1)×(variety of columns −1). For a 2×2 desk, df=1df = 1df=1.
Alpha (αalphaα): The boldness degree of the check. With an alpha of 0.05 (95% confidence), the crucial worth for df=1df = 1df=1 is 3.84.
On this case:
Chi-Sq. Worth = 12.5
Vital Worth = 3.84
Since 12.5>3.8412.5 > 3.8412.5>3.84, the outcomes are statistically important. This means that there’s a relationship between the topic line and the open fee.
If the Chi-Sq. worth had been decrease…
For instance, if the Chi-Sq. worth had been 0.95 (as within the unique situation), it will be lower than 3.84, which means the outcomes wouldn’t be statistically important. This is able to point out no significant relationship between the topic line and the open fee.
8. Interpret your outcomes.
As I dug deeper into statistical testing, I realized that deciphering outcomes correctly is simply as essential as operating the assessments themselves. By means of my analysis, I found a scientific method to evaluating check outcomes.
Robust Outcomes (act instantly)
Outcomes are thought-about sturdy and actionable once they meet these key standards:
95%+ confidence degree. The outcomes are statistically important with minimal danger of being attributable to probability.
Constant outcomes throughout segments. Efficiency holds regular throughout completely different consumer teams or demographics.
A transparent winner emerges. One model persistently outperforms the opposite.
Matches enterprise logic. The outcomes align with expectations or affordable enterprise assumptions.
When outcomes meet these standards, one of the best apply is to behave shortly: implement the profitable variation, doc what labored, and plan follow-up assessments for additional optimization.
Weak Outcomes (want extra information)
On the flip facet, outcomes are sometimes thought-about weak or inconclusive once they present these traits:
Under 95% confidence degree. The outcomes do not meet the brink for statistical significance.
Inconsistent throughout segments. One model performs properly with sure teams however poorly with others.
No clear winner. Each variations present comparable efficiency with no important distinction.
Contradicts earlier assessments. Outcomes differ from previous experiments with no clear clarification.
In these circumstances, the really helpful method is to assemble extra information by retesting with a bigger pattern dimension or extending the check period.
Subsequent Steps Determination Tree
My analysis revealed a sensible determination framework for figuring out subsequent steps after deciphering outcomes.
If the outcomes are important:
Implement the profitable model. Roll out the better-performing variation.
Doc learnings. File what labored and why for future reference.
Plan follow-up assessments. Construct on the success by testing associated components (e.g., testing headlines if topic traces carried out properly).
Scale to comparable areas. Apply insights to different campaigns or channels.
If the outcomes usually are not important:
Proceed with the present model. Stick to the prevailing design or content material.
Plan a bigger pattern check. Revisit the check with a bigger viewers to validate the findings.
Check larger adjustments. Experiment with extra dramatic variations to extend the chance of a measurable impression.
Concentrate on different alternatives. Redirect assets to higher-priority assessments or initiatives.
This systematic method ensures that each check, whether or not important or not, contributes invaluable insights to the optimization course of.
9. Decide statistical significance.
By means of my analysis, I found that figuring out statistical significance comes right down to understanding how one can interpret the Chi-Sq. worth. This is what I realized.
Two key components decide statistical significance:
Levels of freedom (df). That is calculated based mostly on the variety of classes within the check. For a 2×2 desk, df=1.
Vital worth. That is decided by the boldness degree (e.g., 95% confidence has an alpha of 0.05).
Evaluating values:
The method turned out to be fairly simple: you evaluate your calculated Chi-Sq. worth to the crucial worth from a Chi-Sq. distribution desk. For instance, with df=1 and a 95% confidence degree, the crucial worth is 3.84.
What the numbers let you know:
In case your Chi-Sq. worth is bigger than or equal to the crucial worth, your outcomes are statistically important. This implies the noticed variations are actual and never attributable to random probability.
In case your Chi-Sq. worth is lower than the crucial worth, your outcomes aren’t statistically important, indicating the noticed variations might be attributable to random probability.
What occurs if the outcomes aren’t important? By means of my investigation, I realized that non-significant outcomes aren‘t essentially failures — they’re widespread and supply invaluable insights. This is what I found about dealing with such conditions.
Evaluate the check setup:
Was the pattern dimension ample?
Had been the variations distinct sufficient?
Did the check run lengthy sufficient?
Making choices with non-significant outcomes:
When outcomes aren’t important, there are a number of productive paths ahead.
Run one other check with a bigger pattern dimension.
Check for extra dramatic variations which may present clearer variations.
Use the information as a baseline for future experiments.
10. Report on statistical significance to your group.
After operating your experiment, it’s important to speak the outcomes to your group so everybody understands the findings and agrees on the subsequent steps.
Utilizing the e-mail topic line instance, right here’s how I’d method reporting.
If outcomes usually are not important: I might inform my group that the check outcomes point out no statistically important distinction between the 2 topic traces. This implies the topic line alternative is unlikely to impression open charges for future campaigns. We may both retest with a bigger pattern dimension or transfer ahead with both topic line.
If the outcomes are important: I might clarify that Topic Line A carried out considerably higher than Topic Line B, with a statistical significance of 95%. Based mostly on this final result, we must always use Topic Line A for our upcoming marketing campaign to maximise open charges.
Once you’re reporting your findings, listed here are some finest practices.
Use clear visuals: Embody a abstract desk or chart that compares noticed and anticipated values alongside the calculated Chi-Sq. worth.
Clarify the implications: Transcend the numbers to make clear how the outcomes will inform future choices.
Suggest subsequent steps: Whether or not implementing the profitable variation or planning follow-up assessments, guarantee your group is aware of what to do.
By presenting leads to a transparent and actionable means, you assist your group make data-driven choices with confidence.
From Easy Check to Statistical Journey: What I Discovered About Knowledge-Pushed Advertising and marketing
What began as a easy need to check two e-mail topic traces led me down an enchanting path into the world of statistical significance.
Whereas my preliminary intuition was to simply break up our viewers and evaluate outcomes, I found that making actually data-driven choices requires a extra nuanced method.
Three key insights reworked how I take into consideration A/B testing:
First, pattern dimension issues greater than I initially thought. What looks like a big sufficient viewers (even 5,000 subscribers!) won’t truly offer you dependable outcomes, particularly once you’re searching for small however significant variations in efficiency.
Second, statistical significance isn‘t only a mathematical hurdle — it’s a sensible instrument that helps stop expensive errors. With out it, we danger scaling methods based mostly on coincidence relatively than real enchancment.
Lastly, I realized that “failed” assessments aren‘t actually failures in any respect. Even when outcomes aren’t statistically important, they supply invaluable insights that assist form future experiments and preserve us from losing assets on minimal adjustments that will not transfer the needle.
This journey has given me a brand new appreciation for the function of statistical rigor in advertising choices.
Whereas the mathematics might sound intimidating at first, understanding these ideas makes the distinction between guessing and realizing — between hoping our advertising works and being assured it does.
Editor’s word: This put up was initially printed in April 2013 and has been up to date for comprehensiveness.